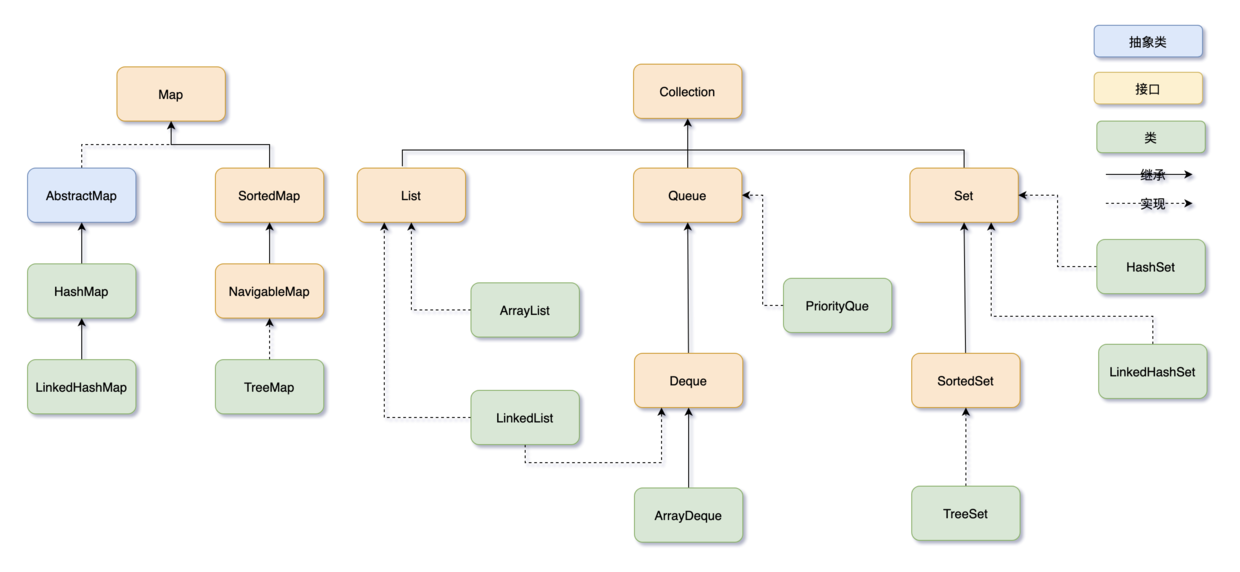
java重拾-集合容器
java重拾-集合容器
ArrayList
- ArrayList 是由数组实现的,支持随机存取,也就是可以通过下标直接存取元素;
- 从尾部插入和删除元素会比较快捷,从中间插入和删除元素会比较低效,因为涉及到数组元素的复制和移动;
- 如果内部数组的容量不足时会自动扩容,因此当元素非常庞大的时候,效率会比较低。
add
扩容过程如下
/**
* 将指定元素添加到 ArrayList 的末尾
* @param e 要添加的元素
* @return 添加成功返回 true
*/
public boolean add(E e) {
ensureCapacityInternal(size + 1); // 确保 ArrayList 能够容纳新的元素
elementData[size++] = e; // 在 ArrayList 的末尾添加指定元素
return true;
}
/**
* 确保 ArrayList 能够容纳指定容量的元素
* @param minCapacity 指定容量的最小值
*/
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) { // 如果 elementData 还是默认的空数组
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity); // 使用 DEFAULT_CAPACITY 和指定容量的最小值中的较大值
}
ensureExplicitCapacity(minCapacity); // 确保容量能够容纳指定容量的元素
}
/**
* 检查并确保集合容量足够,如果需要则增加集合容量。
*
* @param minCapacity 所需最小容量
*/
private void ensureExplicitCapacity(int minCapacity) {
// 检查是否超出了数组范围,确保不会溢出
if (minCapacity - elementData.length > 0)
// 如果需要增加容量,则调用 grow 方法
grow(minCapacity);
}
此处的grow才是真正的扩容方法
新容量为p = min(max(oldCapacity*1.5, minCapacity),MAX\_ARRAY\_SIZE)
/**
* 扩容 ArrayList 的方法,确保能够容纳指定容量的元素
* @param minCapacity 指定容量的最小值
*/
private void grow(int minCapacity) {
// 检查是否会导致溢出,oldCapacity 为当前数组长度
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1); // 扩容至原来的1.5倍
if (newCapacity - minCapacity < 0) // 如果还是小于指定容量的最小值
newCapacity = minCapacity; // 直接扩容至指定容量的最小值
if (newCapacity - MAX_ARRAY_SIZE > 0) // 如果超出了数组的最大长度
newCapacity = hugeCapacity(minCapacity); // 扩容至数组的最大长度
// 将当前数组复制到一个新数组中,长度为 newCapacity
elementData = Arrays.copyOf(elementData, newCapacity);
}
add to index
/**
* 在指定位置插入一个元素。
*
* @param index 要插入元素的位置
* @param element 要插入的元素
* @throws IndexOutOfBoundsException 如果索引超出范围,则抛出此异常
*/
public void add(int index, E element) {
rangeCheckForAdd(index); // 检查索引是否越界
ensureCapacityInternal(size + 1); // 确保容量足够,如果需要扩容就扩容
System.arraycopy(elementData, index, elementData, index + 1,
size - index); // 将 index 及其后面的元素向后移动一位
elementData[index] = element; // 将元素插入到指定位置
size++; // 元素个数加一
}
先扩容, 再移位置, 再放置
remove object
先找到index, 再add to index的逆操作
indexOf
顺序查找找到object的index
lastIndexOf
逆序查找
Collections.binarySearch
需要先sort
LinkedList
- LinkedList 是由双向链表实现的,不支持随机存取,只能从一端开始遍历,直到找到需要的元素后返回;
- 任意位置插入和删除元素都很方便,因为只需要改变前一个节点和后一个节点的引用即可,不像 ArrayList 那样需要复制和移动数组元素;
- 因为每个元素都存储了前一个和后一个节点的引用,所以相对来说,占用的内存空间会比 ArrayList 多一些。
实现了 Stack、Queue、PriorityQueue 的所有功能
节点定义如下
/**
* 链表中的节点类。
*/
private static class Node<E> {
E item; // 节点中存储的元素
Node<E> next; // 指向下一个节点的指针
Node<E> prev; // 指向上一个节点的指针
/**
* 构造一个新的节点。
*
* @param prev 前一个节点
* @param element 节点中要存储的元素
* @param next 后一个节点
*/
Node(Node<E> prev, E element, Node<E> next) {
this.item = element; // 存储元素
this.next = next; // 设置下一个节点
this.prev = prev; // 设置上一个节点
}
}
remove index
顺序遍历到该index再删, 此处有小trick, 如果index>1/2Length就逆序遍历
remove object
顺序查找到该object再删
indexOf object
顺序查找到该object返回index
get index
返回该index的object
Vector
线程安全的ArrayList
Stack
基于Vector实现的栈, 不如dequeue
HashMap
基于对key进行hash来优化随机访问key的速度
- HashMap 中的键和值都可以为 null。如果键为 null,则将该键映射到哈希表的第一个位置。
- 可以使用迭代器或者 forEach 方法遍历 HashMap 中的键值对。
- HashMap 有一个初始容量和一个负载因子。初始容量是指哈希表的初始大小,负载因子是指哈希表在扩容之前可以存储的键值对数量与哈希表大小的比率。默认的初始容量是 16,负载因子是 0.75。
HashSet
只有key的HashMap , value由固定object填充
LinkedHashMap
HashMap + LinkedList 的合体,它使用了哈希表来存储数据,又用了双向链表来维持顺序
LinkedHashSet
只有key的LinkedHashMap , value由固定object填充
TreeMap
实现了 SortedMap 接口,可以自动将键按照自然顺序或指定的比较器顺序排序,并保证其元素的顺序。内部使用红黑树来实现键的排序和查找
既可以key访问, 也可以直接foreach, 顺序即sort的结果
其本质就是红黑树+HashMap实现的, 自动按key排序的map
关于红黑树, 后面数据结构与算法再说
| 特性 | TreeMap | HashMap | LinkedHashMap |
|---|---|---|---|
| 排序 | 支持 | 不支持 | 不支持 |
| 插入顺序 | 不保证 | 不保证 | 保证 |
| 查找效率 | O(log n) | O(1) | O(1) |
| 空间占用 | 通常较大 | 通常较小 | 通常较大 |
| 适用场景 | 需要排序的场景 | 无需排序的场景 | 需要保持插入顺序 |
TreeSet
只有key的TreeMap, value由固定object填充
ArrayDeque
使用数组实现的双端队列, 支持随机访问, 缺点需要连续空间, 扩容开销大
LinkedList
也可以实现Dequeue的功能,
- 底层实现方式不同:LinkedList 是基于链表实现的,而 ArrayDeque 是基于数组实现的。
- 随机访问的效率不同:由于底层实现方式的不同,LinkedList 对于随机访问的效率较低,时间复杂度为 O(n),而 ArrayDeque 可以通过下标随机访问元素,时间复杂度为 O(1)。
- 迭代器的效率不同:LinkedList 对于迭代器的效率比较低,因为需要通过链表进行遍历,时间复杂度为 O(n),而 ArrayDeque 的迭代器效率比较高,因为可以直接访问数组中的元素,时间复杂度为 O(1)。
- 内存占用不同:由于 LinkedList 是基于链表实现的,它在存储元素时需要额外的空间来存储链表节点,因此内存占用相对较高,而 ArrayDeque 是基于数组实现的,内存占用相对较低。
PriorityQueue
实现比较的元素可以放入, 自动排序, 更新复杂度 lgn
License:
CC BY 4.0